![]()
Geração e avaliação de pares questão-sparql
![]()
Jessica Sousa
Ivan Pereira
PUC-Rio
2019-07-09
Geração e avaliação de pares questão-sparql
![]()
com o QApedia
Introdução
- Base de conhecimento do DBpedia:
- A versão do DBpedia 2014 consiste em 3 bilhões de informações (triplas RDF)
- O DBpedia RDF Data Set é hospedado e publicado usando o OpenLink Virtuoso
- A infra-estrutura Virtuoso fornece acesso aos dados RDF da DBpedia por meio de um endpoint SPARQL
Fig. 1: Virtuoso SPARQL Query Editor
Introdução
- Question Answering (QA) corresponde a uma área em ciência da computação que se encontra dentro dos campos de Natural Language Processing (NLP) e Information Retrieval (IR).
- Knowledge Base Question Answering (KBQA):
- QALD-9 - construída por especialistas que mapeiam uma linguagem natural para conversões SPARQL baseadas na base de conhecimento DBpedia 2016-10 (Ngomo, 2018).
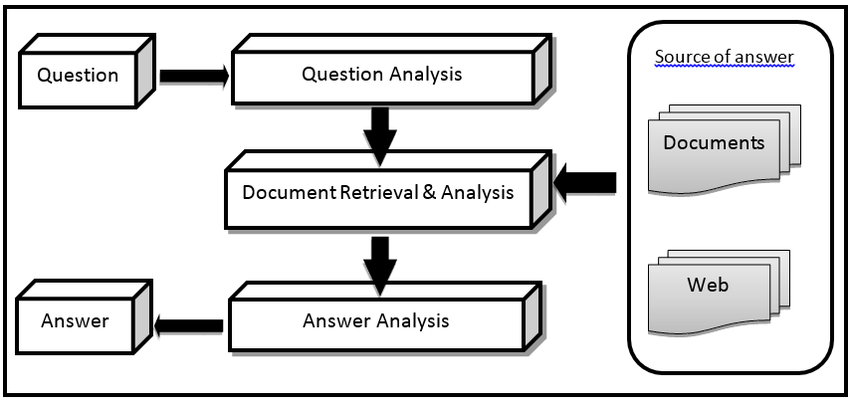
Fig. 2: Arquitetura geral de um sistema de questão-resposta. (Ray, Al Chalabi, and Shaalan, 2015)
Fundamentação
Arquitetura da Neural SPARQL Machine (Soru, Marx, Moussallem, Publio, Valdestilhas, Esteves, and Neto, 2017):
- Generator - A partir de um conjunto de templates de consultas são gerados o conjunto de dados de treino.
- Learner - O aprendendor pegas as entradas em linguagem natural e gera uma sequência que codifica a SPARQL query.
- Interpreter - Realiza a decodificação da SPARQL query.
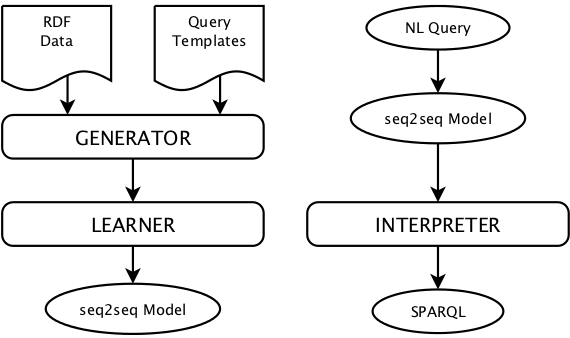
Fig. 3: Arquitetura de uma Neural SPARQL Machine na fase de treinamento (esquerda) e na fase de predição (direita). (Soru, Marx, Moussallem, et al., 2017)
Visão Geral
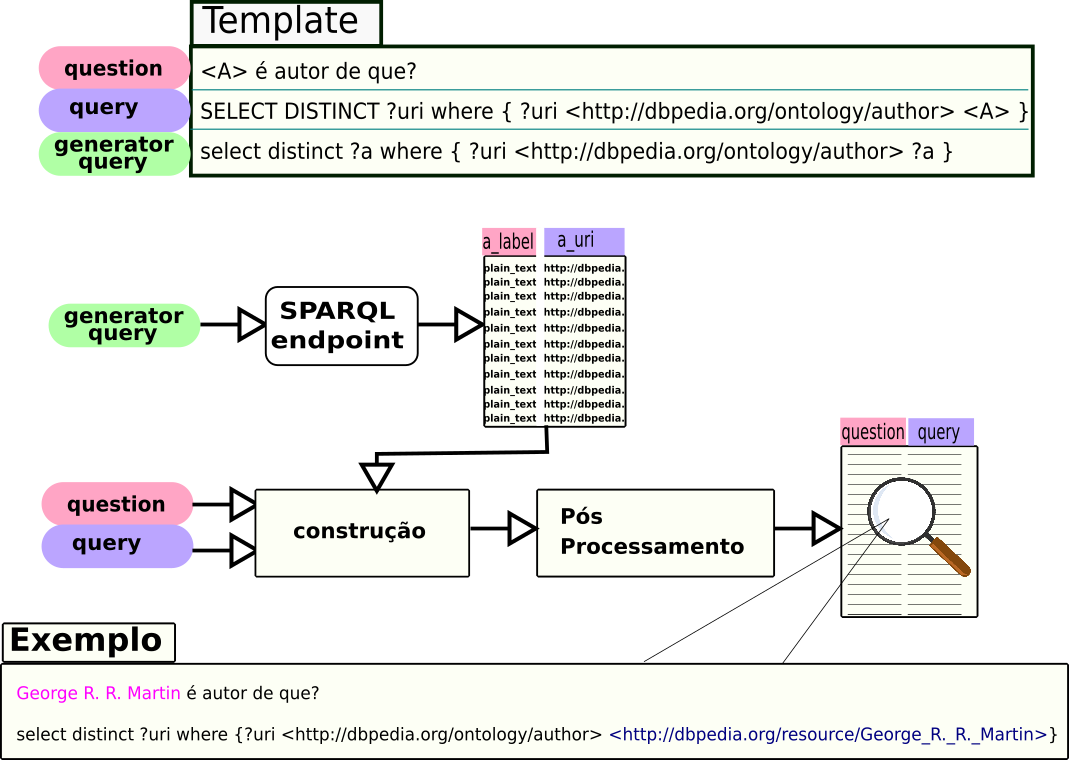
Fig. 4: Visão geral da biblioteca QApedia.
Aumento do dataset
As operações de aumento de carecteres fazem:
- Substituição de caracteres por similares (
OCRAug).
Fig. 5: Substituição por OCR.3
Aumento do dataset
As operações de aumento de carecteres fazem:
- Substituição de caracteres por similares (
OCRAug).Fig. 5: Substituição por OCR.3
- Substituição por caracteres próximos no teclado(
QWERTYAug)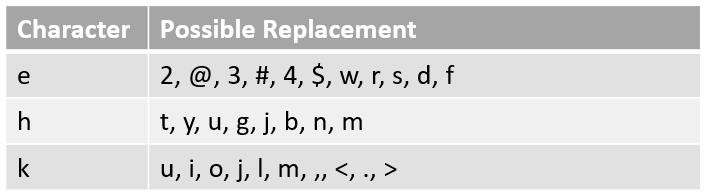
Fig. 6: Substituição por proximidade.4
Aumento do dataset
As operações de aumento de carecteres fazem:
- Substituição de caracteres por similares (
OCRAug).Fig. 5: Substituição por OCR.3
- Substituição por caracteres próximos no teclado(
QWERTYAug)Fig. 6: Substituição por proximidade.4
- Substituição de caracteres aleatoriamente (
RandomCharAug)
Aumento do dataset
As operações de aumento de palavras utilizadas foram feitas com auxílio de outro script e permite:
- A substituição de uma palavra pelo seu sinônimo
- Trocar palavras de lugares aleatoriamente
- Inserir palavras aleatoriamente
- Remover palavras aleatoriamente
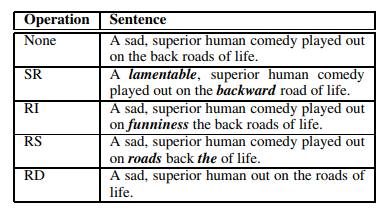
Fig. 7: Técnicas de aumento utilizando palavras.5
[3] A imagem foi retirada da postagem Data Augmentation library for text.
[4] Retirado do Towards of Data Science
RNN

Fig. 8: Arquitetura Encoder-decoder
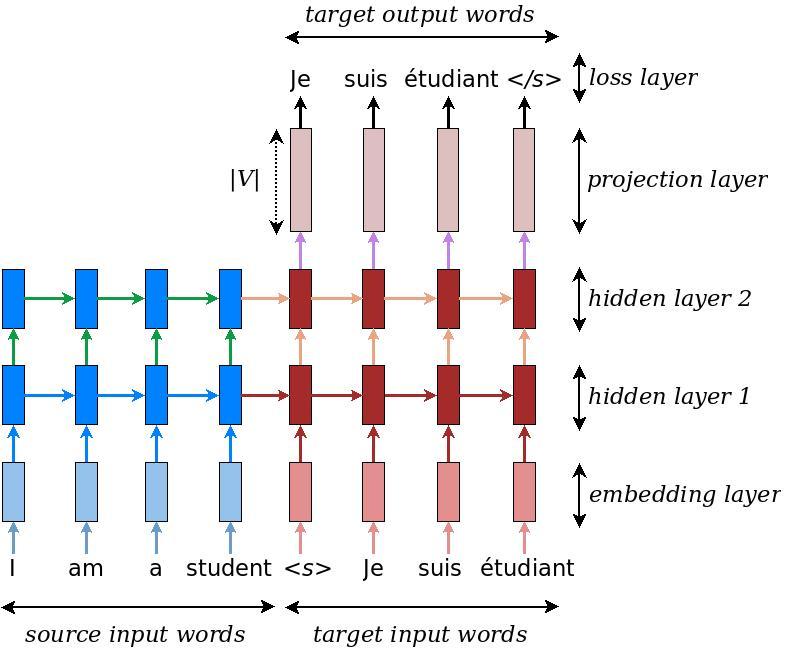
Fig. 9: Neural machine translation
RNN
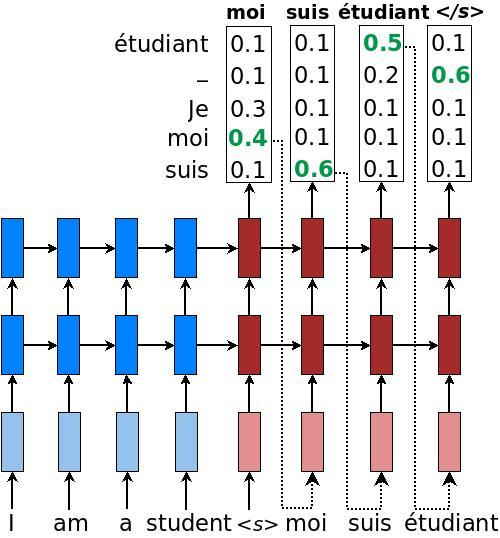
Fig. 10: Greedy decoding
Experimentos
- Sem augmentation
- Treino Loss





.
Fig. 11: Experimentos 1.
Experimentos
- BLEU

.
Fig. 11: Experimentos 2.

